一个器件或者单元的失配,通过MC或者工艺文件可以很轻松地获得。当他们组成电路系统时,这种失配是如何叠加的?比如积分器的增益取决于(Cin1+Cin2)/Cref,系统的增益是G(PGA)*GAIN*(ADC),要回答这个问题,首先就需要解决随机变量加减乘除后的期望与方差如何计算的问题。
直接上结论,电路中有两个Element,E 1 , E 2 E 1 , E 2 ( u , σ ) ( u , σ ) E 1 ( u 1 , σ 1 ) E 1 ( u 1 , σ 1 ) E 2 ( u 2 , σ 2 ) E 2 ( u 2 , σ 2 )
σ ( E 1 ± E 2 ) = σ 1 2 + σ 2 2 σ ( E 1 ⋅ E 2 ) = ( σ 1 σ 2 ) 2 + ( u 2 σ 1 ) 2 + ( u 1 σ 2 ) 2 σ ( 1 E 2 ) ≈ σ 2 u 2 2 , u ( 1 E 2 ) ≈ 1 u 2 σ ( E 1 E 2 ) = σ ( E 1 ⋅ 1 E 2 ) ≈ ( σ 1 σ 2 u 2 2 ) 2 + ( 1 u 2 σ 1 ) 2 + ( u 1 σ 2 u 2 2 ) 2 σ ( E 1 ± E 2 ) = σ 1 2 + σ 2 2 σ ( E 1 ⋅ E 2 ) = ( σ 1 σ 2 ) 2 + ( u 2 σ 1 ) 2 + ( u 1 σ 2 ) 2 σ ( E 2 1 ) ≈ u 2 2 σ 2 , u ( E 2 1 ) ≈ u 2 1 σ ( E 2 E 1 ) = σ ( E 1 ⋅ E 2 1 ) ≈ ( σ 1 u 2 2 σ 2 ) 2 + ( u 2 1 σ 1 ) 2 + ( u 1 u 2 2 σ 2 ) 2
式(1)吻合常识,比如非相关的噪声源的功率叠加,就是平方求和的关系;
式(2)与式(1)一样,是已经被证实结论(实际计算中,划掉的高次项可以忽略)。
正太分布的倒数的分布,是一个数学难题。这里给出了一个近似估计,当σ < μ / 30 σ < μ / 3 0
当解决完1/E的的问题,利用式(3)和式(2),式(4)的问题就迎刃而解了。
在模拟电路中,那么在比例电路中,比如 Cpacitive-Coupled-Amplifer, SigmaDelta-ADC-Discreate-Integrator, SAR-CDAC中,我门更关心的是相对比例偏差,单位尺寸器件的相对标准偏差 :
σ c = σ u σ c = u σ
如果分别有 M M N N E 1 E 1 E 2 E 2 E 1 / E 2 = M / N E 1 / E 2 = M / N 相对标准偏差 是一个非常简洁的表达式:
σ ( E 1 E 2 ) u ( E 1 E 2 ) = ( 1 u 2 σ 1 ) 2 + ( u 1 σ 2 u 2 2 ) 2 M N = ( 1 N u M σ ) 2 + ( M u N σ ( N u ) 2 ) 2 M N = σ c 1 M + 1 N u ( E 2 E 1 ) σ ( E 2 E 1 ) = N M ( u 2 1 σ 1 ) 2 + ( u 1 u 2 2 σ 2 ) 2 = N M ( N u 1 M σ ) 2 + ( M u ( N u ) 2 N σ ) 2 = σ c M 1 + N 1
如果要完全证明上述结论,不仅需要理解随机信号中的很多问题(概率密度分布函数,联合概率密度分布函数,互相关等知识,待完成),还需要有较好的数学功底去求解积分、级数等等。其实这个问题可以通过小学数学去直观理解。
令人感叹的是,当一个数学高考140分+的复旦/上交的和一个本硕清华的,被问及如何求解失配误差的问题时,都在1分钟内不约而同地给出了下述结论。回顾工程发展史,数学理论推导似乎总有些事后诸葛亮的嫌疑,而对事物“本质”的直观通俗理解,才是一个优秀工程师的应有的素养。
直观理解的方法是:加法的平方求和是常识;乘法忽略掉高阶项后,可以转换为加法;除法可以转化为乘法再转换为加法 。最终都是平方求和小学问题。具体来说:
计算乘法时
( u 1 + e 1 ) ( u 2 + e 2 ) = u 1 u 2 + u 1 e 2 + u 2 e 1 + e 1 e 2 ≈ u 1 u 2 + u 1 e 2 + u 2 e 1 ( u 1 + e 1 ) ( u 2 + e 2 ) = u 1 u 2 + u 1 e 2 + u 2 e 1 + e 1 e 2 ≈ u 1 u 2 + u 1 e 2 + u 2 e 1
当我们计算失配误差时,是不需要考虑DC项u 1 u 2 u 1 u 2 u 1 , 2 ≫ e 1 , 2 u 1 , 2 ≫ e 1 , 2
σ 2 ( E 1 ⋅ E 2 ) ≈ ( u 1 σ 2 ) 2 + ( u 2 σ 1 ) 2 σ 2 ( E 1 ⋅ E 2 ) ≈ ( u 1 σ 2 ) 2 + ( u 2 σ 1 ) 2
计算除法时,当u 1 , 2 ≫ e 1 , 2 u 1 , 2 ≫ e 1 , 2
( u 1 + e 1 ) ( u 2 + e 2 ) = u 1 u 2 1 + e 1 / u 1 1 + e 2 / u 2 ≈ u 1 u 2 ( 1 + e 1 u 1 ) ( 1 − e 2 u 2 ) = u 1 u 2 ( 1 + e 1 u 1 − e 2 u 2 + e 1 e 2 u 1 u 2 ) = u 1 u 2 + e 1 u 2 − u 1 e 2 u 2 2 + e 1 e 2 u 2 2 ( u 2 + e 2 ) ( u 1 + e 1 ) = u 2 u 1 1 + e 2 / u 2 1 + e 1 / u 1 ≈ u 2 u 1 ( 1 + u 1 e 1 ) ( 1 − u 2 e 2 ) = u 2 u 1 ( 1 + u 1 e 1 − u 2 e 2 + u 1 u 2 e 1 e 2 ) = u 2 u 1 + u 2 e 1 − u 2 2 u 1 e 2 + u 2 2 e 1 e 2
再次利用平方求和关系,忽略掉高次项,得到
σ 2 ( E 1 E 2 ) ≈ ( σ 1 u 2 ) 2 + ( − u 1 σ 2 u 2 2 ) 2 σ 2 ( E 2 E 1 ) ≈ ( u 2 σ 1 ) 2 + ( − u 2 2 u 1 σ 2 ) 2
如果稍微运用点大学知识,去解释为何有如下的近似的时候,就需要用到幂级数了
1 1 + x ≈ 1 − x 1 + x 1 ≈ 1 − x
展开1/(1+x)的当x→0时的幂级数,忽略掉高次项
1 1 + x = 1 − x + x 2 − x 3 + x 4 + ⋯ 1 + x 1 = 1 − x + x 2 − x 3 + x 4 + ⋯
(*Mathematica 13.2*)
Series[1/(1 + x), {x, 0, 4}]
MOS
TSMC测试方法是Vt by maximum-gm method (sweep Vg@Vd=0.1Vm Vb=0V), 这里的Vtgm近似等于Vth,最终统计为以下模型,WL的单位是um,Vtgm的单位是mV
σ ( V t g m ) = σ 0 W L σ ( V t g m ) = W L σ 0
TSMC 0.18um Mixed Signal,
MIM
运用我们的直观理解去计算,TSMC的测试方法统计如下标准差(C1=C2=C),其实是器件本身失配比率的标准差的sqrt(2)倍
2 ( C 1 − C 2 ) C 1 + C 2 = 0 + 2 e 1 − 2 e 2 2 C + e 1 + e 2 C 1 + C 2 2 ( C 1 − C 2 ) = 2 C + e 1 + e 2 0 + 2 e 1 − 2 e 2
定义σ ( C ) σ ( C ) C C
σ ( 2 ( C 1 − C 2 ) C 1 + C 2 ) ≈ 2 2 σ ( C ) 2 C = 2 σ ( C ) C σ ( C 1 + C 2 2 ( C 1 − C 2 ) ) ≈ 2 C 2 2 σ ( C ) = C 2 σ ( C )
TSMC统计的结果用如下函数表述,统计的标准差是失配的百分比%,WL的单位是um
σ ( R a t i o ) = σ 0 W L σ ( R a t i o ) = W L σ 0
TSMC 0.18um Mixed Signal,
【注意】其实TSMC给出的统计结果,Ratio%,是当前WL对应的Capcitance的2 2 2 2
例如mim_2fF, W=L=10um,则有
σ ( R a t i o ) = ( 1.2102 / 10 ) % = 0.12 % σ ( R a t i o ) = ( 1 . 2 1 0 2 / 1 0 ) % = 0 . 1 2 %
该电容的大小为200fF,它的失配应该为
200 fF × 0.12102 % ÷ 2 = 171.148 aF 2 0 0 fF × 0 . 1 2 1 0 2 % ÷ 2 = 1 7 1 . 1 4 8 aF
该示例已经过cadence仿真确认,仿真结果平均值201.3f,标准差173.2a。
RES
运用我们的直观理解去计算,TSMC的测试方法统计如下标准差(R1=R2=R),其实是器件本身的失配比率标准差的sqrt(2)倍
σ ( 2 ( R 1 − R 2 ) R 1 + R 2 ) ≈ 2 σ ( R ) R σ ( R 1 + R 2 2 ( R 1 − R 2 ) ) ≈ R 2 σ ( R )
统计的结果用如下函数表述,统计的标准差是失配的百分比%,WL的单位是um
σ ( R a t i o ) = σ 0 W L σ ( R a t i o ) = W L σ 0
TSMC 0.18um Mixed Signal,
通过PDK的失配模型,进行蒙特卡洛仿真,其实已经预设了所有element的失配(随机误差)分布是彼此独立,没有关联的。这在信号与系统中叫不相关,在统计分析中叫协方差为零。但这显然不是事实!
mismatch或者local mismatch指的是一片wafer上器件之间的失配,也就是我们通常意义上理解的失配。process mc或者global mismatch指的是wafer与wafer之间的失配,可以简单理解为coner的高斯统计模型分布。电路设计中,一个只要求比例正确的设计,只需要考虑local mismatch。但是要考虑一个绝对值在量产后的分布特性,就需要process+mismatch同时仿真了(90%肯定时正确的,有待进一步确认)。
模拟电路设计中,会把需要的匹配的器件放得彼此靠近,同时遵循某种对称关系以应对所处环境参数的梯度变化,如切割应力,参杂浓度,WPE(井边缘参杂浓度的梯度变化),LOD(浅沟道隔离STI对应变硅的压力)等等。
所以当周围环境一致且彼此靠近的器件,彼此的失配误差,是小于PDK模型给出的标准差的(事实如此吗?有待验证)。当变量彼此存在相关关系后,问题就变得有些复杂了(涉及协方差?有待进一步学习)。
这里,通过2个简单的例子,尝试去直观理解“相关”的影响。
% From BeiYangMan
% 创建2个随机序列,vn(n)=x与vn(n-1)=y
vn=randn(1,10001); % 标准差为1长度1001的序列
x=vn(2:end);
y=vn(1:end-1);
% v(n)=x与vn(n-1)=y是独立不相关的,因此v(n)-v(n-1)的的方差是平方求和的关系,1^2+1^2=2
z=x+y;var(z)
% v(n)=x与v(n)+vn(n-1)=z其实已经彼此相关了,因为v(n)+vn(n-1)中有彼此相关的成分
% 由于x,z相关,结果将不是sqrt(2)^2+1^2=3
% p=x+z=2x+y,2x与z是独立不相关的,再次利用平方求和,2^2+1^2=5
p=x+z;var(p)
这个例子还可以有不同的理解,方差本质是功率,那( 1 + z − 1 ) ( 1 + z − 1 ) ( 1 + z − 1 ) + 1 ( 1 + z − 1 ) + 1
为什么说两个彼此相关了呢?( 1 ) ( 1 ) ( z − 1 ) ( z − 1 ) ( 1 + z − 1 ) ( 1 + z − 1 ) ( 1 − z − 1 ) ( 1 − z − 1 )
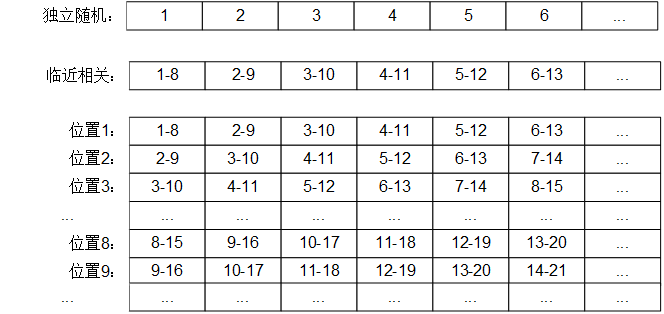
如果我们认为,版图中临近的8个具有相关性,那么每一个器件和包含有他周围8个的随机误差,可以简单的建模为
σ n ′ = σ n + σ n + 1 + σ n + 2 + σ n + 3 + σ n + 4 + σ n + 5 + σ n + 6 + σ n + 7 8 σ n ′ = 8 σ n + σ n + 1 + σ n + 2 + σ n + 3 + σ n + 4 + σ n + 5 + σ n + 6 + σ n + 7
接着,接着我们分别计算:
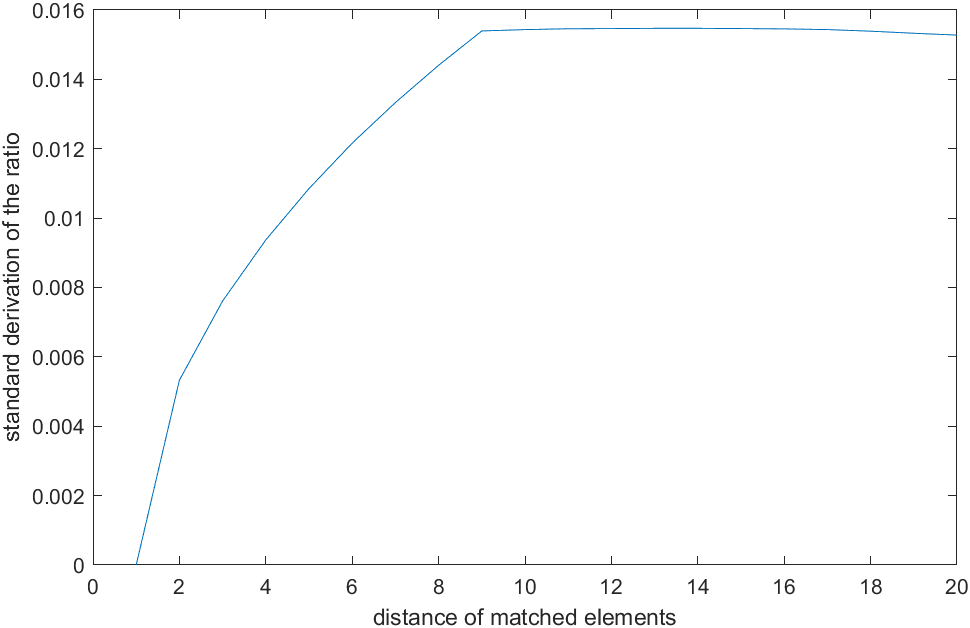
统计所有列的数据的标准差,横坐标为距离,纵坐标为比例标准差。观察到当间距小于8时,失配随距离增大而增大,而超过我们设定的8后,失配标准差趋向于固定值(也就是说变成了完全独立的随机变量)。
有意思的现象是,我们去观察这个图形,这就是空间域上的noise-shaping,求和代表一阶integtrator,平均除以8代表OSR,求器件彼此的失配相当于反馈做差,这就是一个空间域上的MOD1。
% From BeiYangMan
clear;clc;
% 独立随机变量
sigma=3;dc=100;a=dc+sigma*randn(1,10008);
% 创建以临近8的相关模型
for cnt=1:8 xa(cnt,:)=a(cnt:10000+cnt); end
y=sum(xa)/8;
% 创建列表,分别为位置1-N
for cnt=1:20 ya(cnt,:)=y(cnt:9900+cnt); end
% 统计 [比例标准差]vs[间距] 的数据并作图
for cnt=1:20 stdya(cnt)=std(ya(1,:)./ya(cnt,:)); end
plot(1:20,stdya)
xlabel("distance of matched elements");ylabel("standard derivation of the ratio")
通常意义上,随机信号,噪声是高斯白噪声,【高斯】,是【概率密度分布函数】服从高斯分布Gaussian distribution:
p ( x ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) , m e a n = μ , v a r i a n c e = σ 2 p ( x ) = 2 π σ 1 exp ( − 2 σ 2 ( x − μ ) 2 ) , m e a n = μ , v a r i a n c e = σ 2
解释【白】之前,就涉及到随机信号的功率谱密度了。
随机信号是一个功率信号,因为其能量是无限的,因此不能用FS分析。同时作为一个功率信号,我们必须加窗T截断后,分析其在1/T这个频率内的特性,其实是假定了该信号的频率小于1/2T,但是噪声信号没有周期性,永远不会重复,因此也不能用FT去分析。
这个永远不会重复的特性可以用自相关来表示,接着Winer-Khintchine theorem证明了随机信号功率与自相关的关系,这里直接给出结论:
∫ − ∞ ∞ S x x ( ω ) d ω = 1 T ∫ − T 2 T 2 x 2 ( t ) d t ∫ − ∞ ∞ S x x ( ω ) d ω = T 1 ∫ − 2 T 2 T x 2 ( t ) d t
= P o w e r = E ( X 2 ) = ∫ − ∞ ∞ x 2 p ( x ) d x = r x x ( 0 ) = P o w e r = E ( X 2 ) = ∫ − ∞ ∞ x 2 p ( x ) d x = r x x ( 0 )
回归到数学问题来,随机比例方差之所以要去估计而不是精确求解,本质式概率分布密度函数积分不收敛,简单说就是无穷大时概率不为零,有重尾特性,有人说是柯西分布?只能说类似吧?),有待进一步学习。
What is the Mean and Standard Deviation of the division of two random variables?