¶ Binary Adder Introduction
所谓加法器,就是对二进制数去做加法运算
- 半加器包含两个输入A和B,以及A+B求和的结果S以及进位CO。这里的 A+B=S,每个数可以是 1bit 也可以是多bit,但是他们都具有相同的bit数,这样一定会有溢出,所以就有了进位CO,例如 A<2:0> + B<2:0> = {CO, S<2:0>};
- 全加器的区别在于会考虑低位的进位,这对于扩展加法器很有用,其计算过程相当于 CI + A<2:0> + B<2:0> = {CO, S<2:0>}
本文中,我们会包含 Gate Level / Transistor Level 电路实现以及仿真分析,利用 VerilogA 实现高效的验证工作,巧妙应用了 Calculator 中的函数,并对整个设计进行了 Layout Floor Plan。
¶ Gate Level Realization
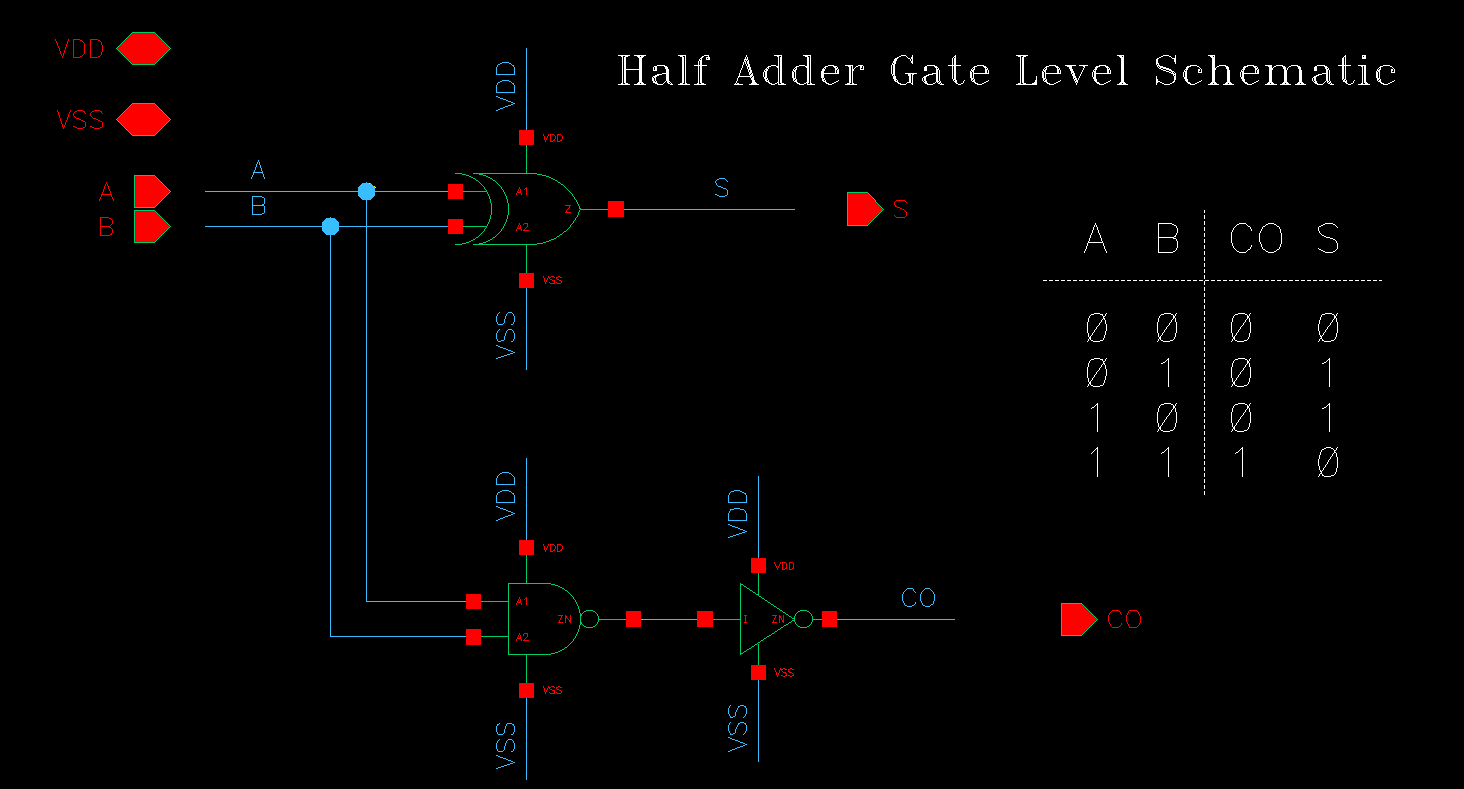
下图是一个 single-bit Half Adder 的门级电路(Gate-Level Schematic),其实从目标出发,做出真值表,然后卡诺图化简后可以得到逻辑实现方式,这种方式很好但实在是工作后用得太少了,绝大多数的编码工作就是一些类似 3-8 译码器的工作,比较直接,很少涉及弯弯绕绕,笔者这里不再赘述。
这里并没有直接用与门,而是用了一个与非门+非门实现与门,因为在CMOS Transistor Level 实现时就是这样做的。
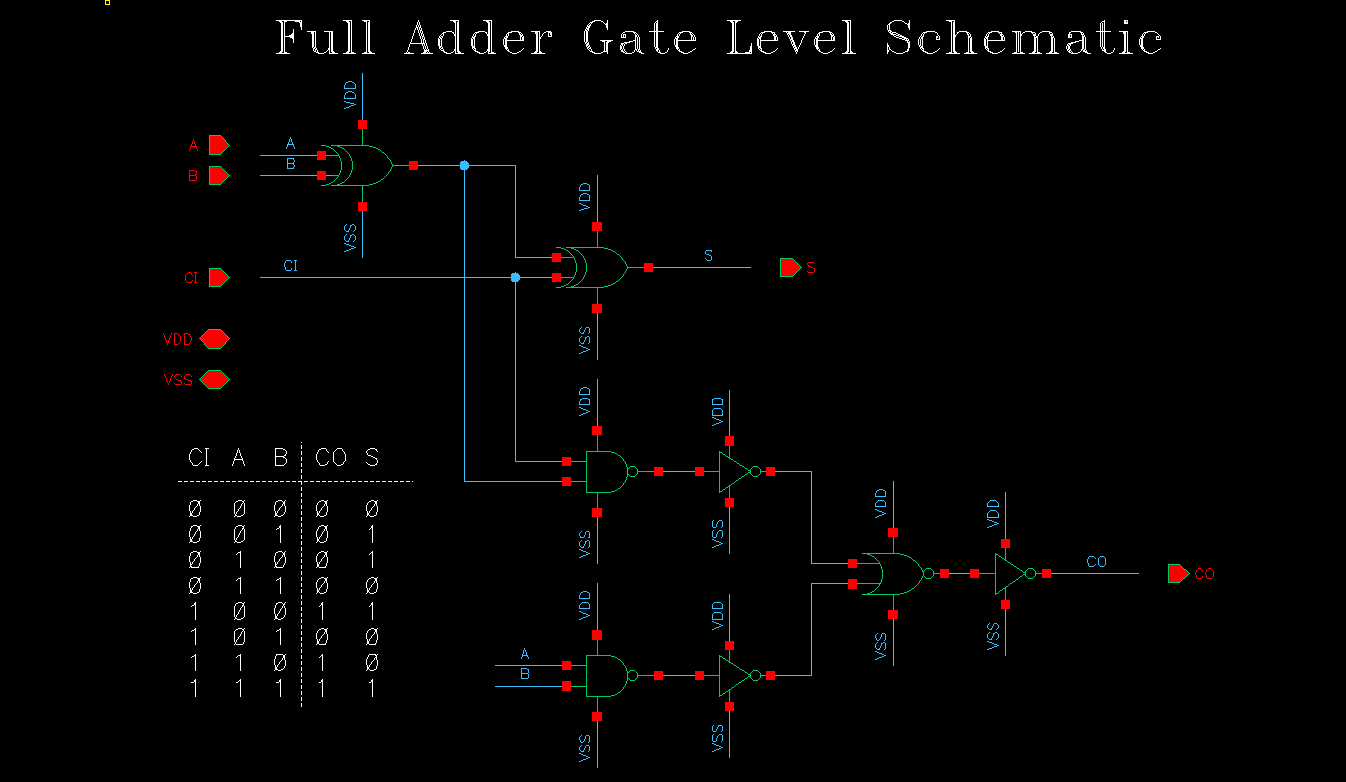
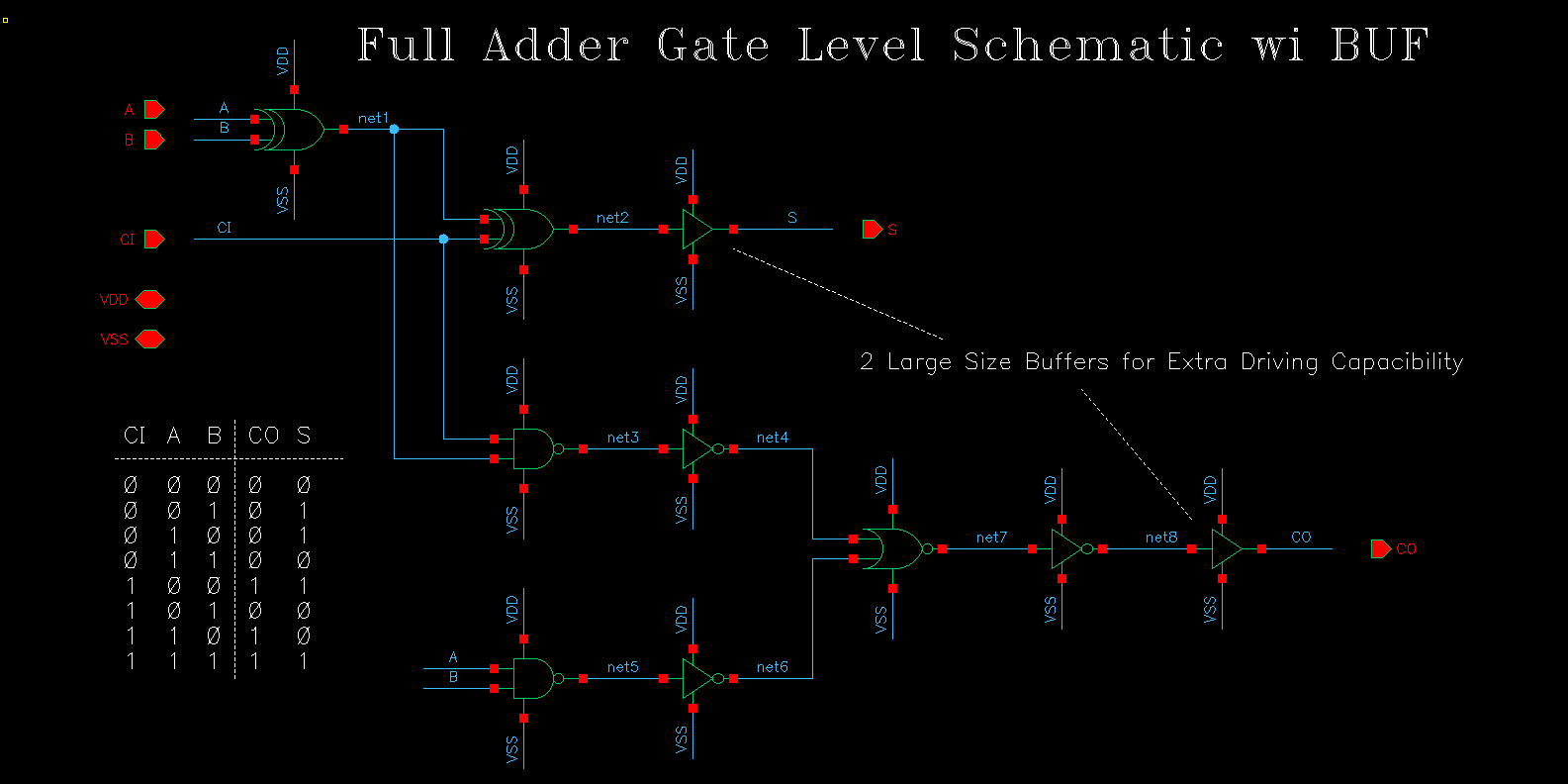
下图是一个 single-bit Full Adder 的门级电路(Gate-Level Schematic), 这里在输出端增加了额外的 BUFFER,其实就是由两个大尺寸的 Invertor 实现,用于驱动提高驱动能力(用于驱动具有大电容或者小阻抗的低阻节点)
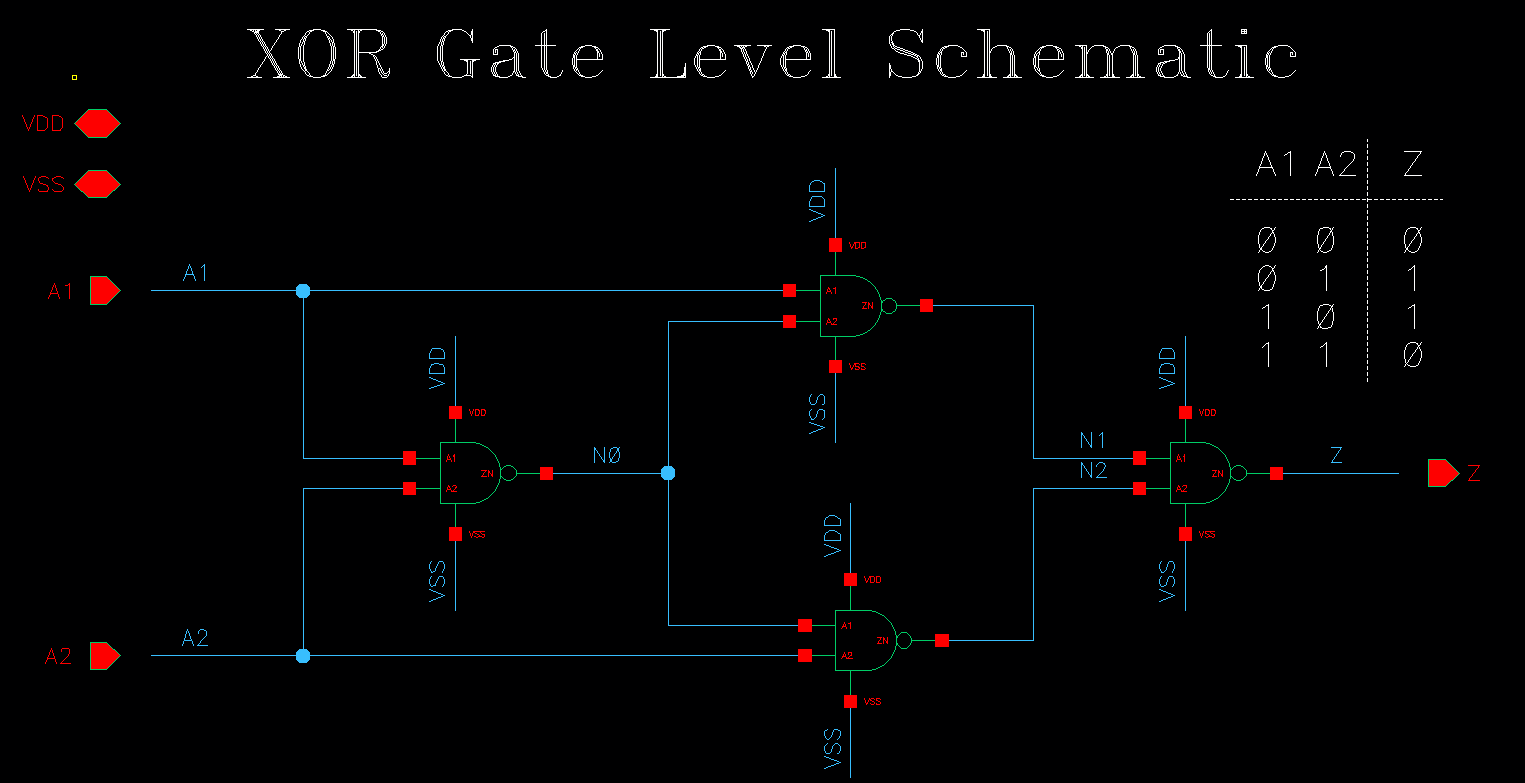
这里值得一提的是是异或门的实现,异或门可以由与非门实现
¶ Transistor Level Realization
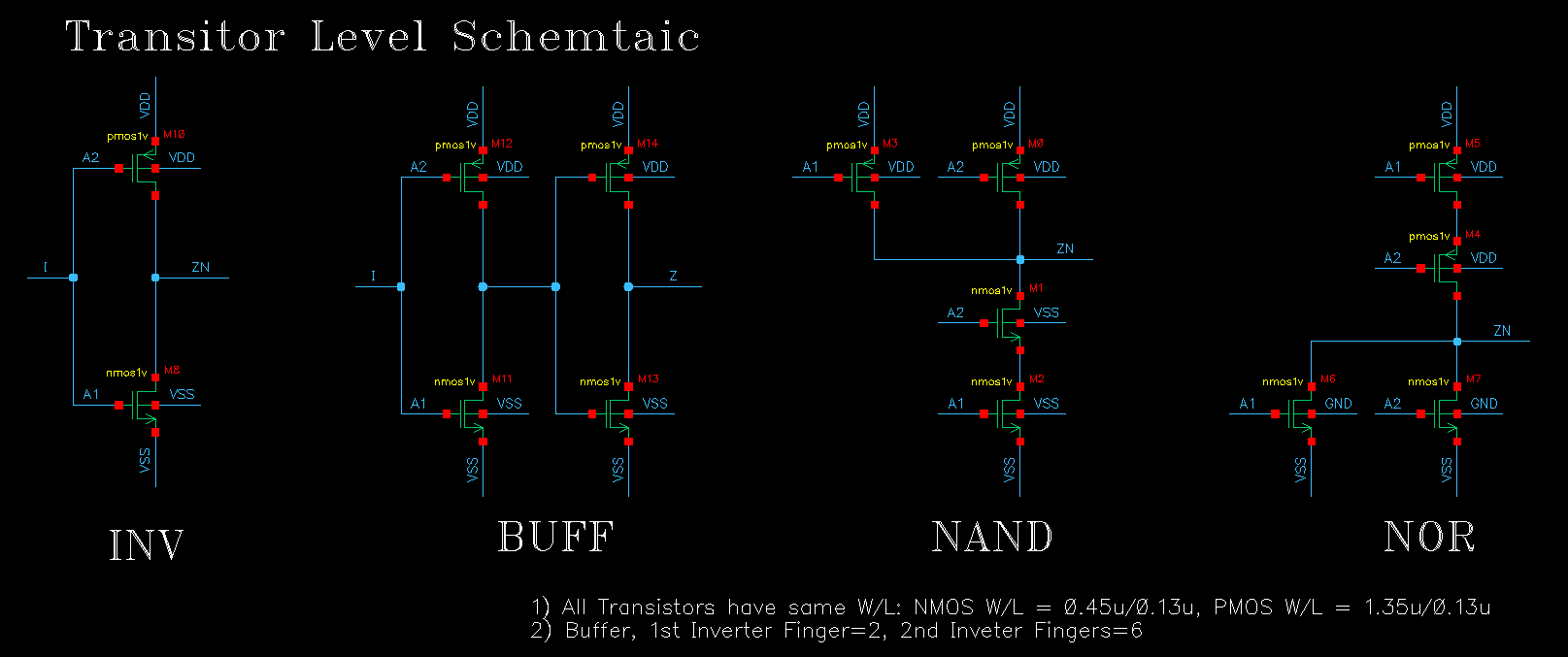
我们真实用到的逻辑门电路,只有非门/与非门/或非门,这里为了优化驱动能力,单独优化了两个反相器去做 Buffer。值得注意的是,我们所以器件的单 Finger 尺寸都使用固定的,之后我们会看到,版图实现中非常高效。
¶ Simulation Single-Bit Full Adder
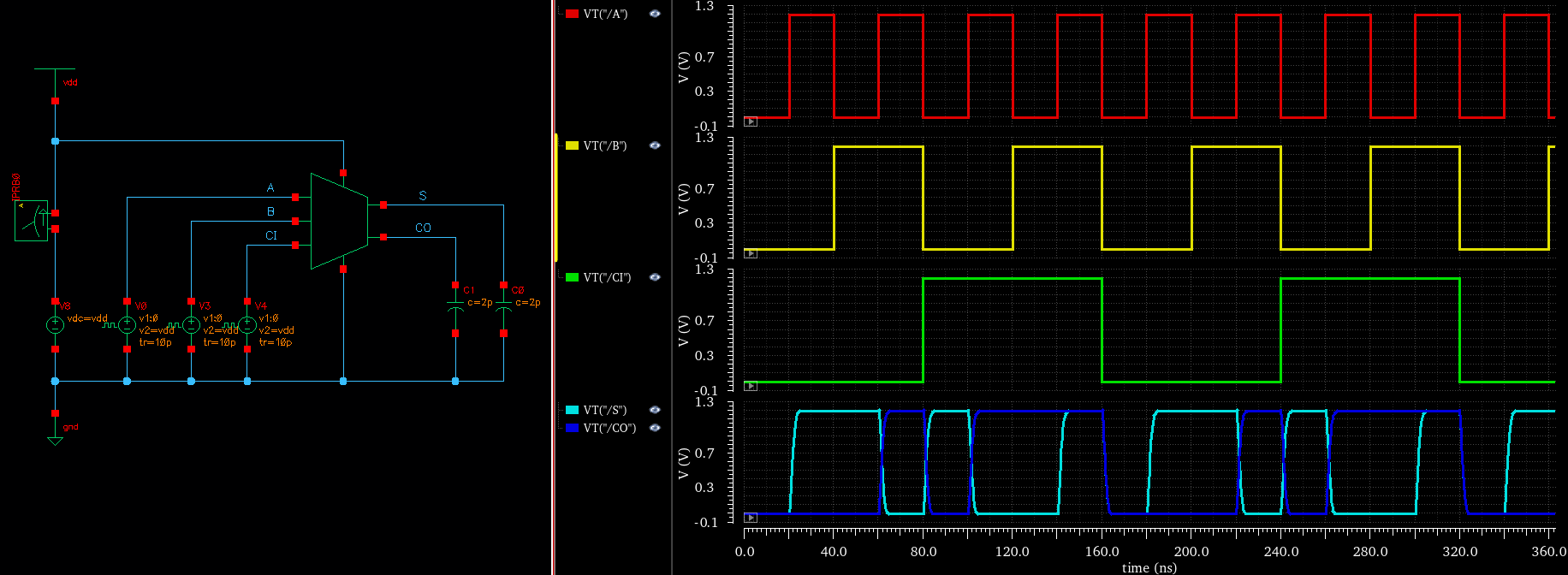
如下图,创建仿真的 TESTBENCH,输入信号 A/B/C 分别用 40ns/80ns/160ns的方波给出,这里可以周期遍历 种不同的输入组合,使用 analogLib - vpulse 给出,这里我们使用了 variable vdd 和 tp,让仿真环境更加灵活,设置 tr/tf=10ps 是为了尽可能让激励信号更加陡峭趋于理想,同时避免太过理想的信号导致仿真器收敛失败 :
- vpulse for A: Voltage 1 = 0, Voltage 2 = vdd, Period = 2*tp, Delay time = 1*\tp, Rise time = 10p, Fall time = 10p
- vpulse for B: Voltage 1 = 0, Voltage 2 = vdd, Period = 4*tp, Delay time = 2*\tp, Rise time = 10p, Fall time = 10p
- vpulse for CI: Voltage 1 = 0, Voltage 2 = vdd, Period = 8*tp, Delay time = 4*\tp, Rise time = 10p, Fall time = 10p
接着我们测量延迟,测量之前我们需要有如下认知:
- 其实延迟分为上升沿延迟和下降沿延迟,分别取决于PMOS和NMOS的驱动能力,由于空穴和电子迁移率大约有3倍的差别,所以在本文的示例中 PMOS W0idth 是 NMOS Width 的 3 倍;
- 不同逻辑单元的延迟不一致,取决于路径上的导通阻抗,例如对于 NAND 门,并联的PMOS和串联的NMOS组成,输出信号上升过程是由PMOS主导,并联阻抗较小;输出信号下降过程由NMOS主导,串联阻抗较大;这就会导致NAND门具有 tr < tf 的天生特性。
- S的延迟与CO的延迟不一致,主要与传输路径有关,使用相同的逻辑单元,越长的传输路径会导致更大的延迟;
这里我们只是粗略的做了下分类,就已经发现 delay 测量要分很多种情况,这里我们简单一点,直接观察在这样的激励下,那个变化沿具有最大的 delay,就认为该 Half-Adder 的 Delay time 是多少,我们观察到信号在如下边沿中,具有相对最大的 Rising Delay 和 Falling Delay。
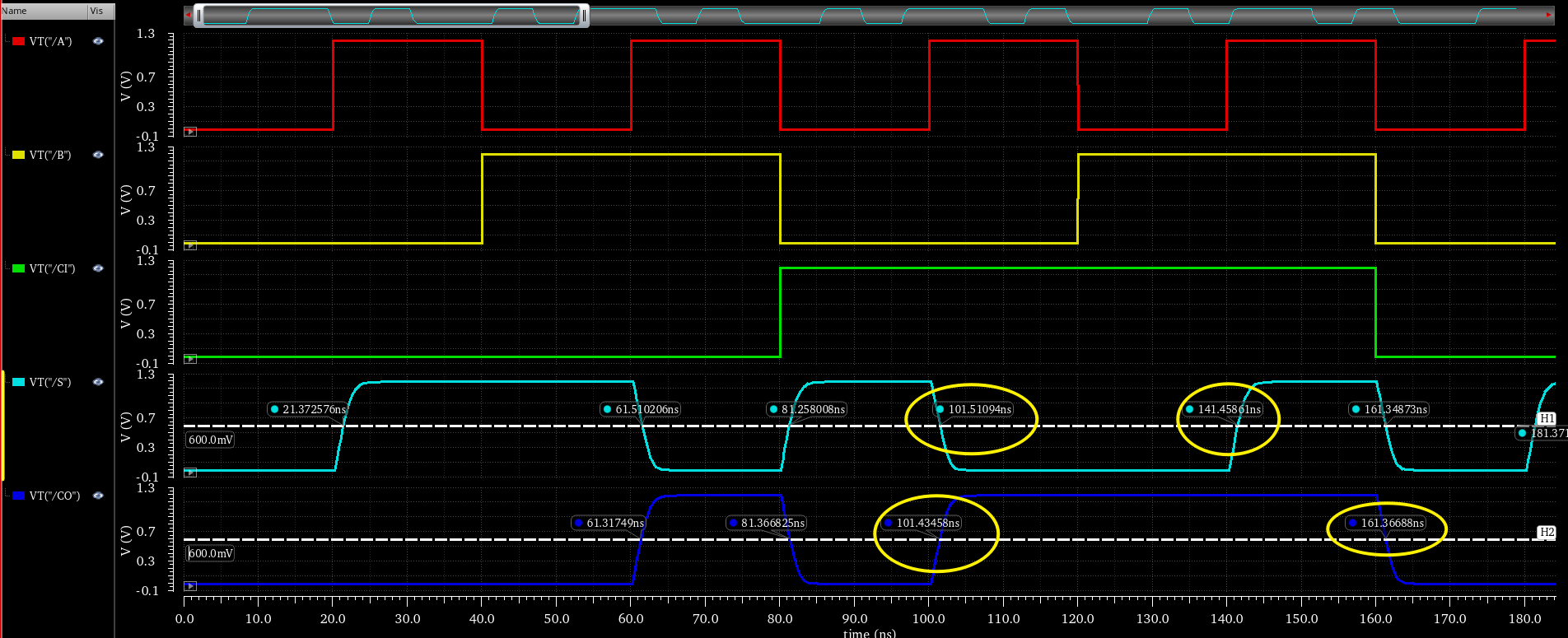
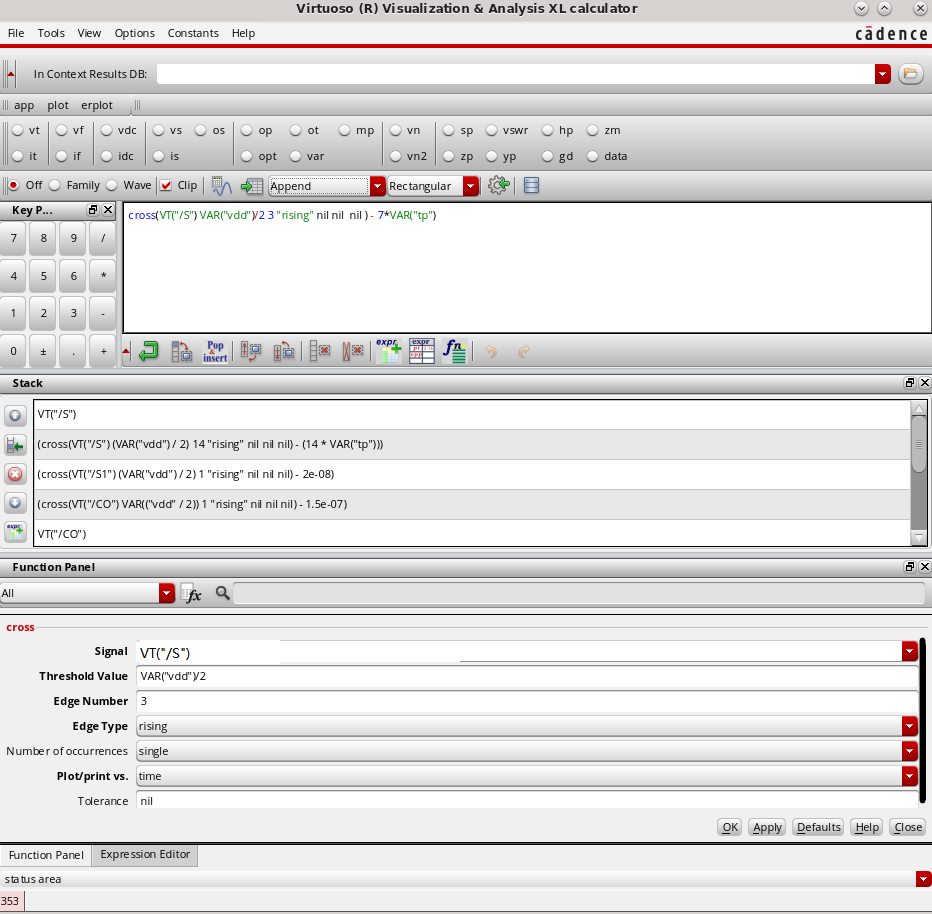
还记得我们见激励的变化延设置在了 tp 的整数倍上(10ps 的 tr/tf 可以忽略),这样在 calculator 中可以很方便的 extract delay time,例如我们发现 VT("/S") 这个信号,在第 3 个 rising edge 具有最大的延迟,我们评判变化生效的时间为电压超过 VAR("vdd")/2,同时激励信号在 140ns 7*VAR("tp"),这样利用 cross 函数已知 y 求 x 等到对应的变化时间,就可以测量 Delay Time 了。
我们将这个 Outputs 的 Name 设置为 td_rise_S,同理还可以需要设置 td_fall_S td_rise_CO td_fall_CO
另外一个比较关键的参数就是功耗,对于功耗我们有如下理解:
- 所谓功耗,就是平均功率,就是平均电流乘以电源电压,为什么是平均电流而非均方根电流呢?因为电源上通常会有非常大的 Decoupling Capacitor(起滤波稳压作用),只有净流出的电流才是真正从电源上抽取的,由于电路动态工作过程会出现芯片反向向电源供电的情况,其实这时候电荷就暂存在了 Decoupling Capacitor 中供之后使用。所以我们计算功耗时,统计的是平均电流而非均方根电流。
- 数字电路的功耗分为3部分:
- 部分是电流对负载电容和寄生电容的充放电消耗掉的,其实就是 CVF 电流,和总的电容大小,电源电压,工作频率都成线性比例;
- 另一部分就是 N管和P管在 Gate 处于 VDD/2 附近时会同时导通,这样一部分电流会浪费流到地去而不是去对电容节点充放电,所以我们会期望信号的变化延尽可能的陡峭,但是这也是一个 trade-off 设计,更加陡峭优化了后级门电路的直接VDD-GND穿通电流,但对于前级驱动级本身缺需要更大的尺寸和更大的功耗。
- 最后一部分是漏电,即使管子处于截止状态,仍然会有电流流过,主要在高温下比较严重,超低功耗电路的设计中需要尤其关注这点。
这里我们通过 analogLib - iprobe 获取电流,通过 average 函数获取平均电流后,用表达式 average(IT("/IPRB0/PLUS"))*VAR("vdd") 求得平均功率,这里 IT() 是用来获取 transient current 的,VAR() 是用来获取 variable 的。
这里我们直接在 ADEL 中,设置完 Corner 后进行仿真,Coner 对电源变化 ±10%,仿真3个温度点,以及5个 MOS 管的工艺角。这里 tt/ss/ff/sf/fs 中,第一个字母代表 nmos 的 process corner 是 typical slow fast,第二个字母代表 pmos 的 process corner。
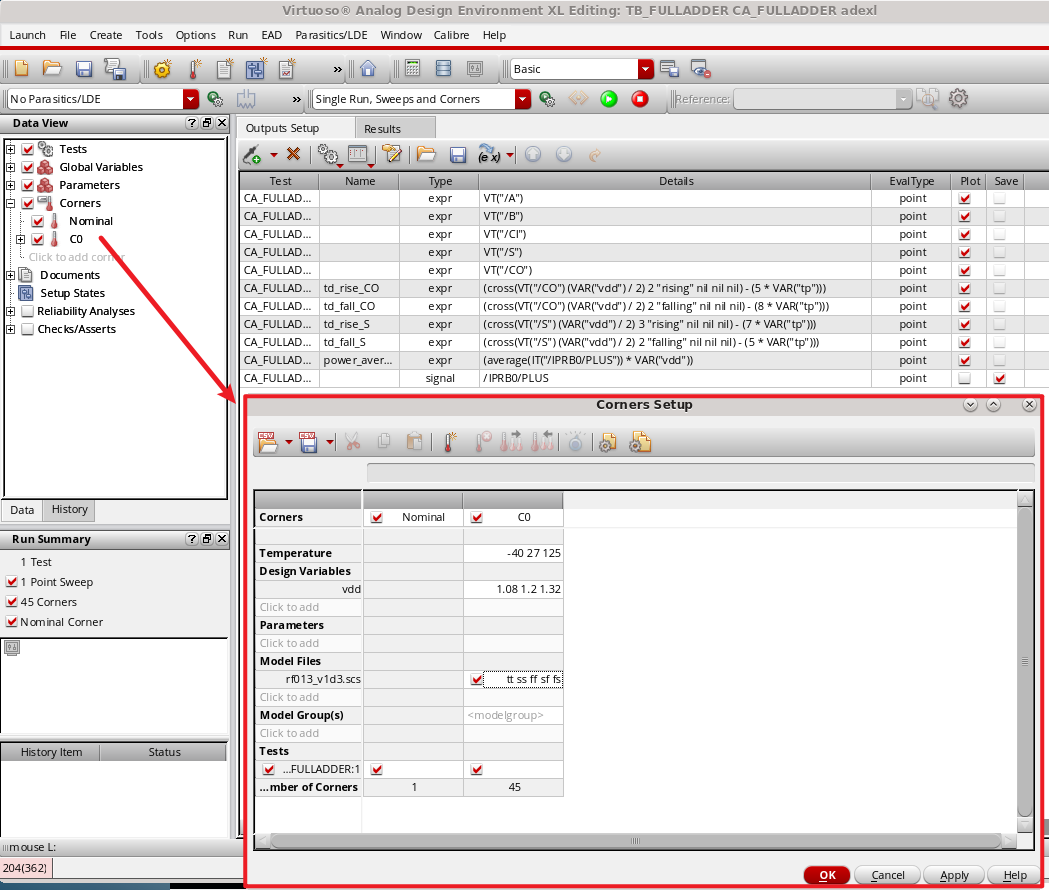
仿真后,我们选择视图为 Detail Transpose,然后单击 td_rise_CO 和 power_average去排序,可以看到
- 对于延迟, 低压/高温/Slow 下延迟最高,高压/低温/Fast 下延迟最小;
- 对于平均功率(功耗),高压/高温/Fast 最高,低压/低温/Slow 最小;
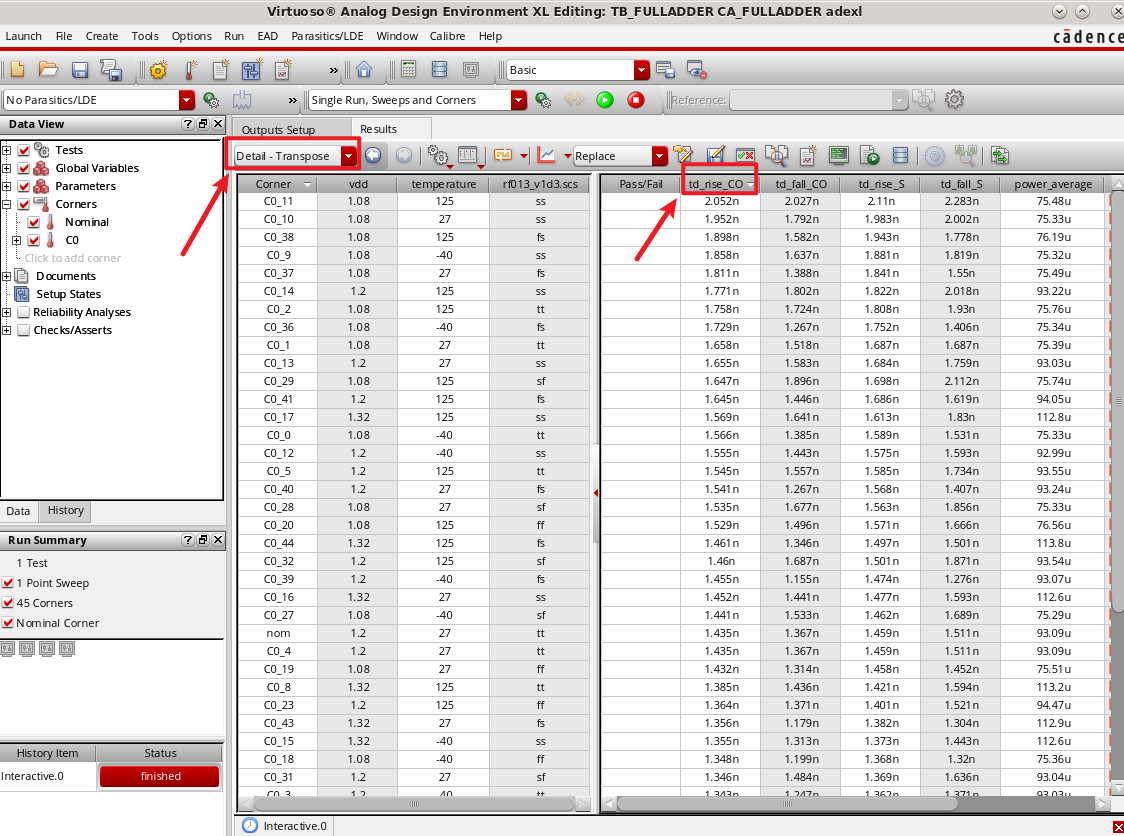
¶ Multi-Bit Full Adder Implementation
¶ Gate Level Realization
我们简单思考,就可以发现对于 Multi-Bit,只需要将 Full Adder 做以下级联即可扩展
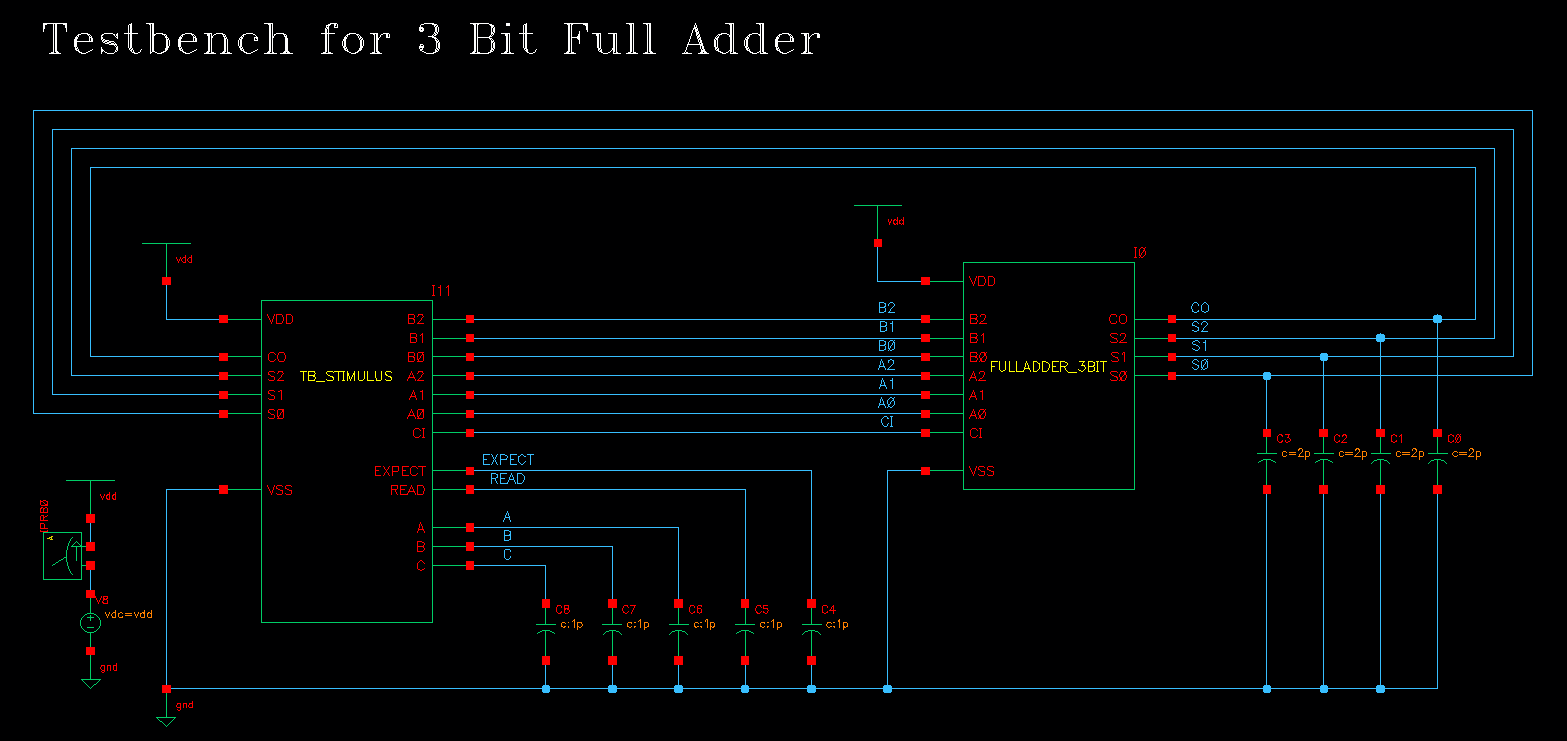
¶ Testbench Using Verilog-A
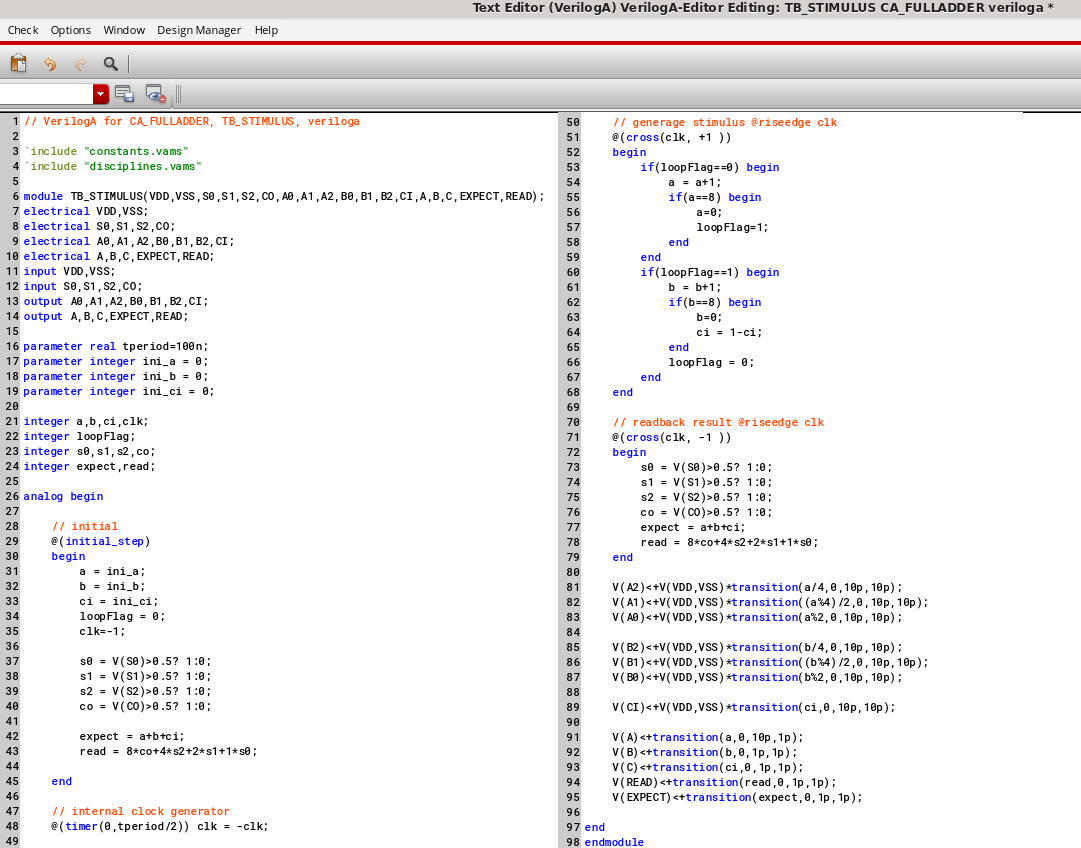
这里我们做了如下的 Testbench,这里辅助仿真的 Stimulus 模块做了如下操作:
- 产生了内部振荡器,周期可以通过 parameter 控制
- 振荡器上升沿:输出遍历的二进制激励
A<2:0>, B<2:0>, CI,一共有7个激励,那么意味着有 种输入组合,并将二进制激励转化为十进制数A,B,C方便观察,同时计算得到EXPECT=A+B+C - 振荡器下降沿:读回了 3-Bit-Full-Adder的
CO,S<2:0>,并转换成十进制数READ,方便与EXPECT比较
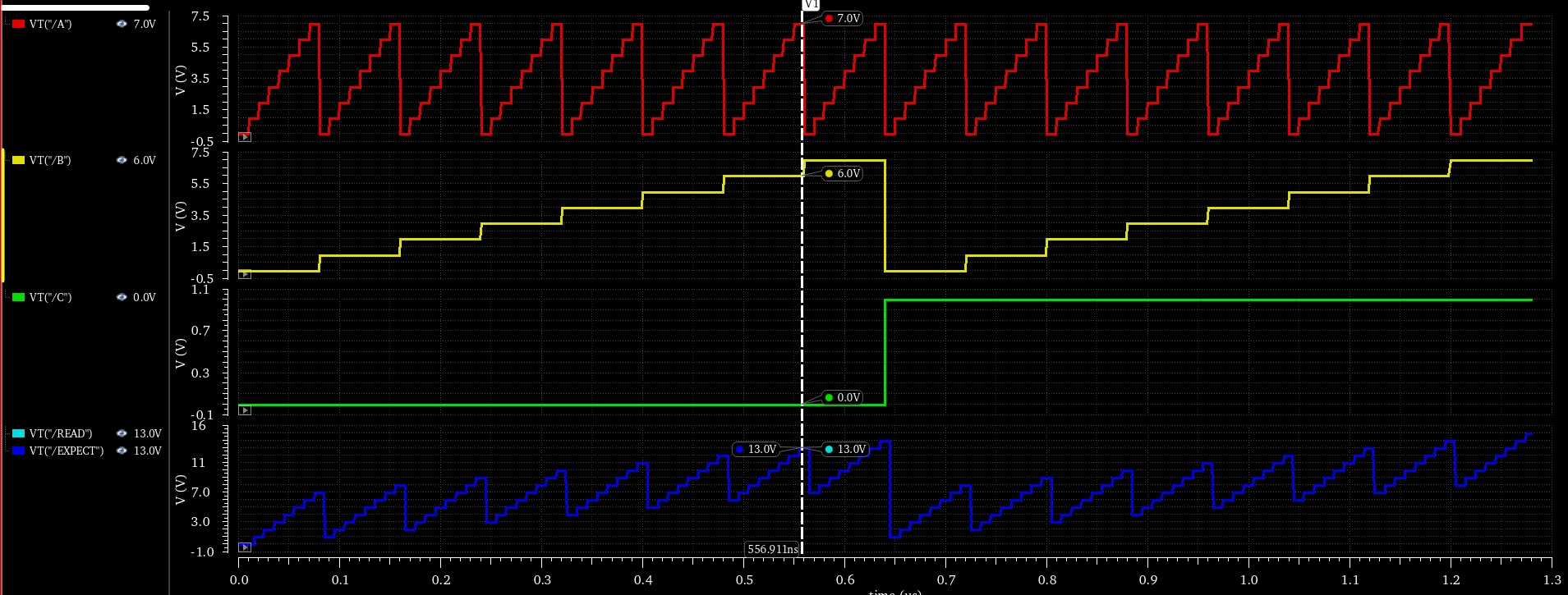
仿真验证的典型波形如下,例如在光标时刻:
- A=7,{A2,A1,A0}=111
- B=7,{A2,B1,B0}=111
- C=0,CI=0
- EXPECT=14
- READ=14,{CO,S2,S1,S0}= 1110
这里使用 VerilogA语法实现的 Stimulus 如下,不作赘述:
¶ Extracting Delay Time with Smart Method
此时信号变得多了起了,我们需要统计 CO S2 S1 S0 四个信号的上升/下降延迟,同时还有不同的激励顺序/激励组合,如果精细分析的话,这会是一项非常繁琐的任务。这里我们使用一种更为聪明的办法。
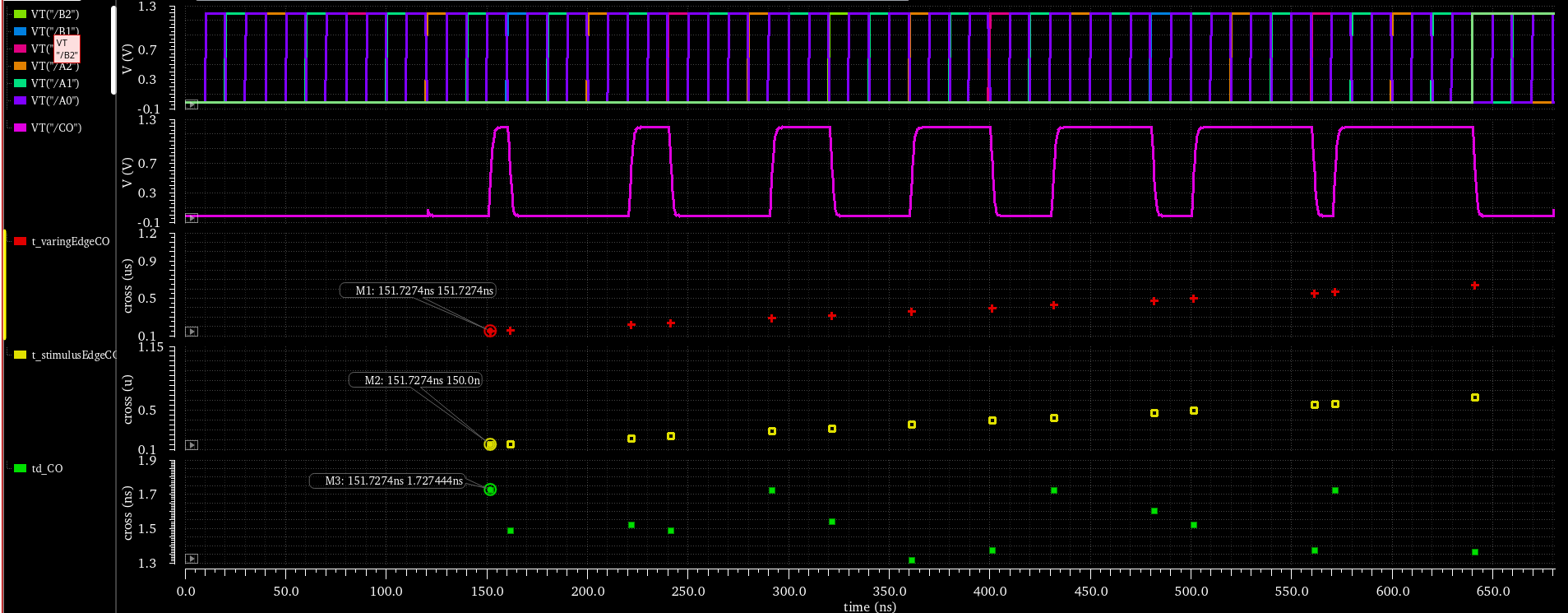
- 首先不区分 rising/falling,我们都去提取 either,而且不去提取单个 single,而是全部提取 multiple,将这个信号命名为
t_varingEdgeCO,表示 CO 信号变化延的时刻,具体的公式为cross(VT("/CO") (VAR("vdd")/2) 1 "either" t "time" nil) - 接着我们知道,激励一定是在 10ns 的整数倍时刻变化,我们将
t_varingEdgeCO/10ns 取整后,再次乘以 10ns,就可以得到对应激励变化的时刻了,例如我们发现t_varingEdgeCO= 31.25ns,int(31.25n/10n)*10n=30n,对应的公式为int(t_varingEdgeCo/VAR("tp"))*VAR("tp"),并命名为t_stimulusEdgeCO - 这样我们可以得到
td_CO等于t_varingEdgeCO-t_stimulusEdgeCO,接这个我们可以对其求平均值/最大值/最小值,average(td_CO)max(td_CO)min(td_CO)得到数值型的结果
效果如下,在151.7274ns 探测到的 VT("\CO") 的变化,所以 t_varingEdge_CO = 151.7274ns,接着通过求整的方式得到 t_stimulusEdge_CO = 150ns,那么 td_CO = 1.7274ns
¶ Import Verilog Structural Instantiation Design
¶ Structural Instantiation
使用代码生成原理图,可以使用 CDL 语言描述,也可以使用 skil 脚本实现,然而这些并不是一个数字电路真正的设计过程。数字电路设计的过程更多是进行 RTL Verilog 的 coding/design,验证通过后,使用工具综合成 Gate Level 的电路实现,然后利用工具进行自动布局布线并进行后反仿验证。
这里的思想是,首先使用 Verilog 写好全加器的 Gate Level Netlist,然后利用 Cadence 的 Verilog Import 功能,导入到 Cadence 生成 Schematic。这里除了 INV/BUF/NAND/NOR 这个需要做基础的设计之外,其它的模块使用 例化 的方式去实现。代码中对这几个基础模块按照 Verilog 语法进行了逻辑实现。

¶ Import Verilog in Cadence
导入流程如下,需要注意的是,我们在导入的库 CA_FULLADDER_IMPORT 中,预先放置了已经设计好的 Cell 及其 Schematic
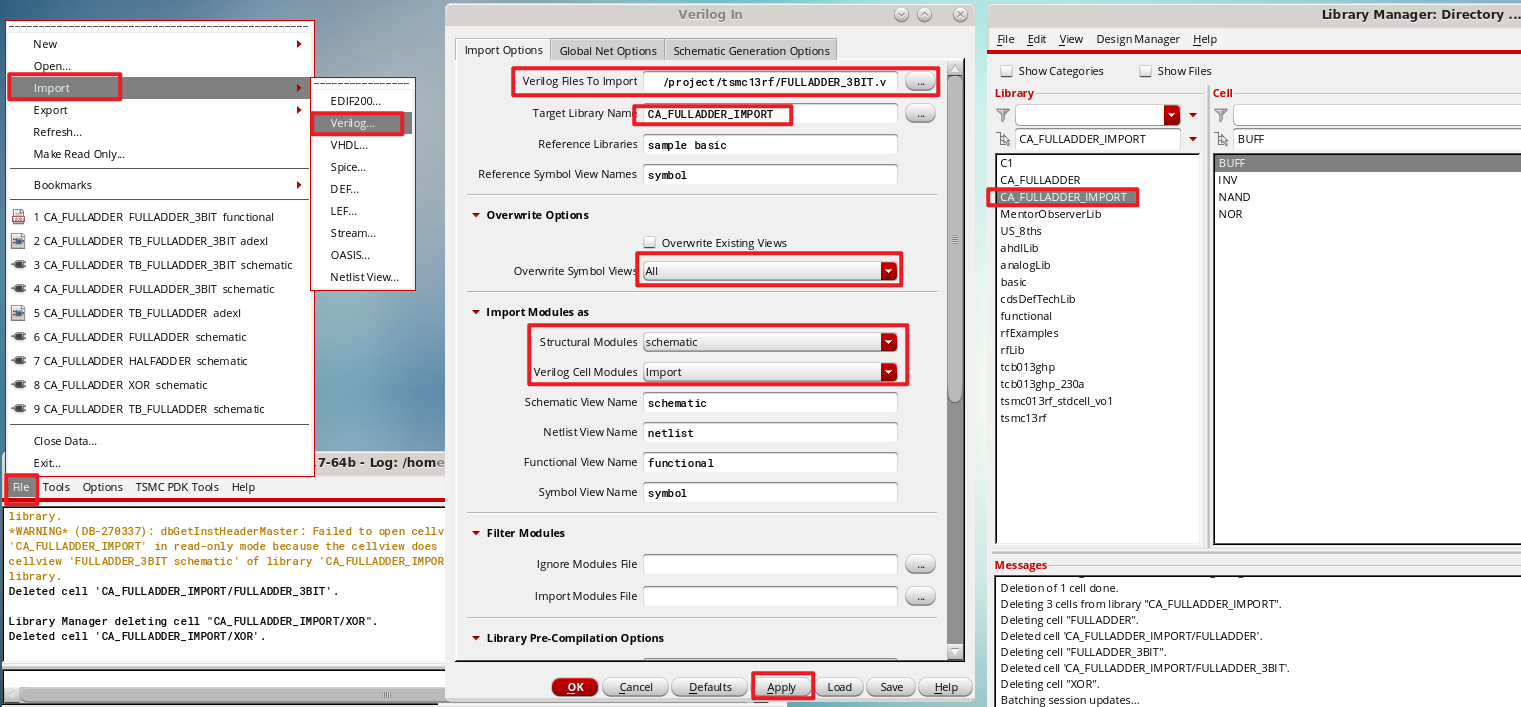
导入之后效果图如下:
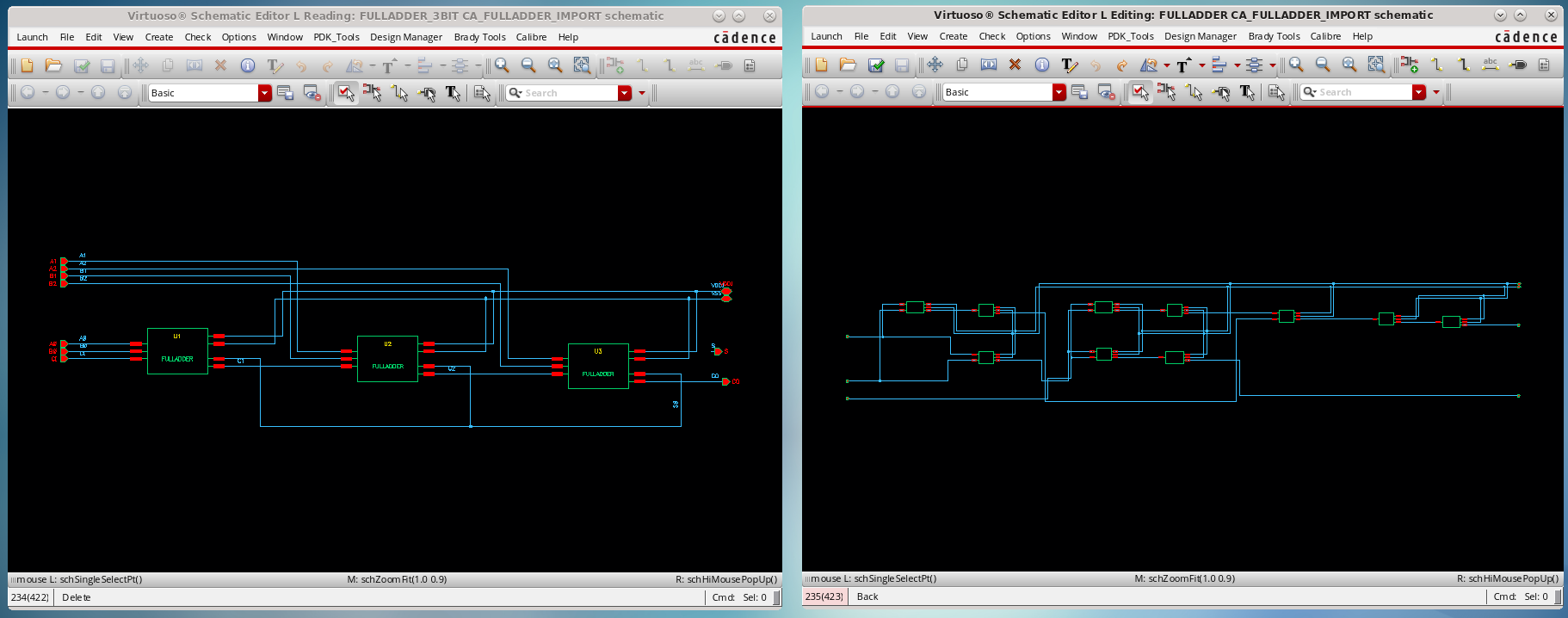
¶ Layout
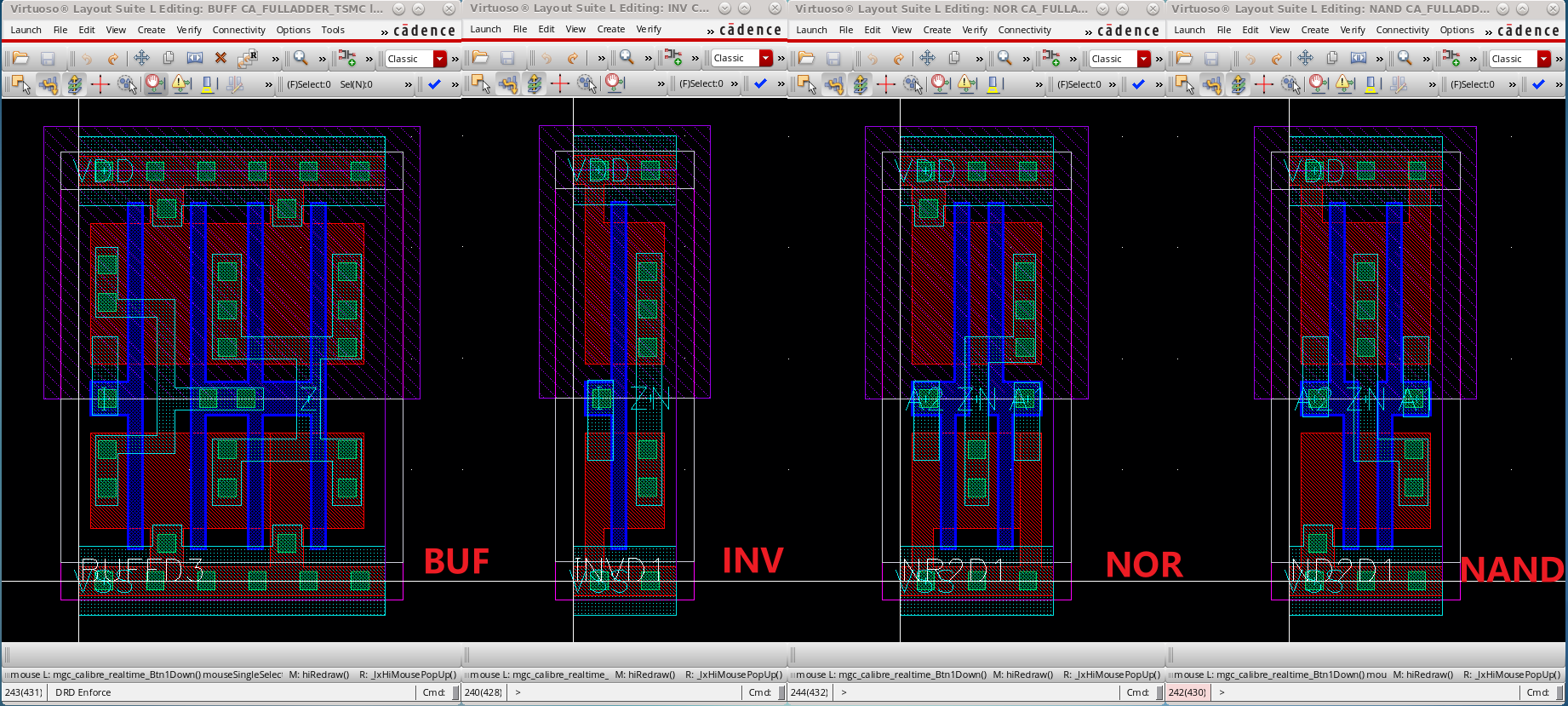
基本思想是,对4个基础模块进行 Transistor 级别的 Layout 绘制工作,他们具有相同的 Pitch 高度(其实就是保证所有单个MOS管具有相同的W),这样可以方便地进行拼接
做好 Single-Bit FULLADDER 后,顶层调用3个 FULLADDER 构成 3BIT-FULLADDER
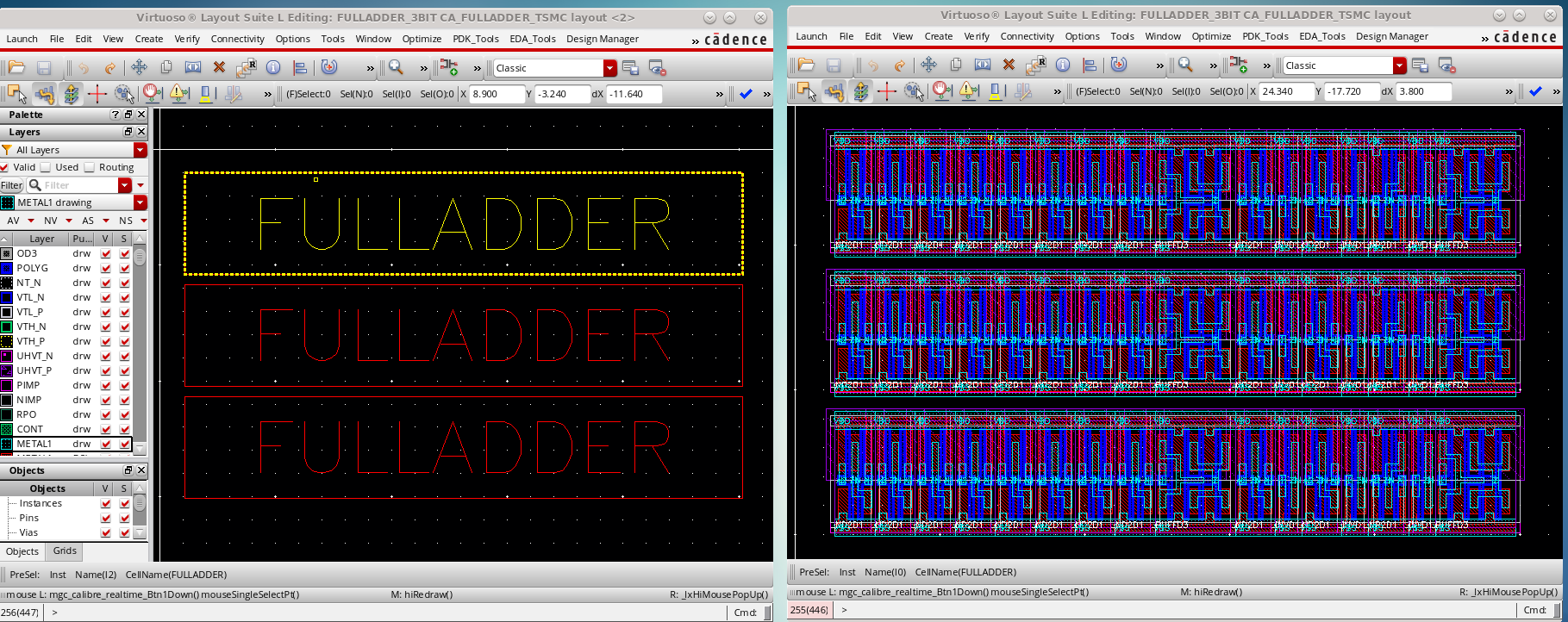
这里我们只进行了 Floor Plan,并没有去做精细的连接。一个简单的方式是,METAL1 是其逻辑单元内部连线,使用METAL2进行横向连线,METAL3进行纵向连线,一个优秀的 LAYOUT 设计在完成这样的设计时,使用的互连线不会超过 3 层。